
MORE FROM THE STACKS

EDITOR’S NOTE: There are literally thousands of journals published around the world that relate to the disability community. It is virtually impossible to capture even a fraction of them. HELEN receives "stacks" of journals and selectively earmarks what we feel are "must read" articles of interest for our readers. It's a HELEN perk!

ANCOR Issues Findings from 2024 State of America's Direct Support Workforce Crisis Survey
This fall, in our continued effort to better understand how providers navigate long-term shortages of qualified direct support professionals (DSPs), ANCOR fielded our fifth annual survey of community-based providers of intellectual and developmental (I/DD) services.
This year's survey garnered responses from 496 distinct organizations delivering services in 47 states plus the District of Columbia.
The following data points are among the key findings from the State of America’s Direct Support Workforce Crisis 2024:
Long-term underinvestment in home- and community-based services, together with stagnant and insufficient reimbursement rates, have hampered the ability of community providers to offer DSPs competitive wages and benefits. This has led to an exodus of qualified workers from the field, which was deeply exacerbated by the COVID-19 pandemic.
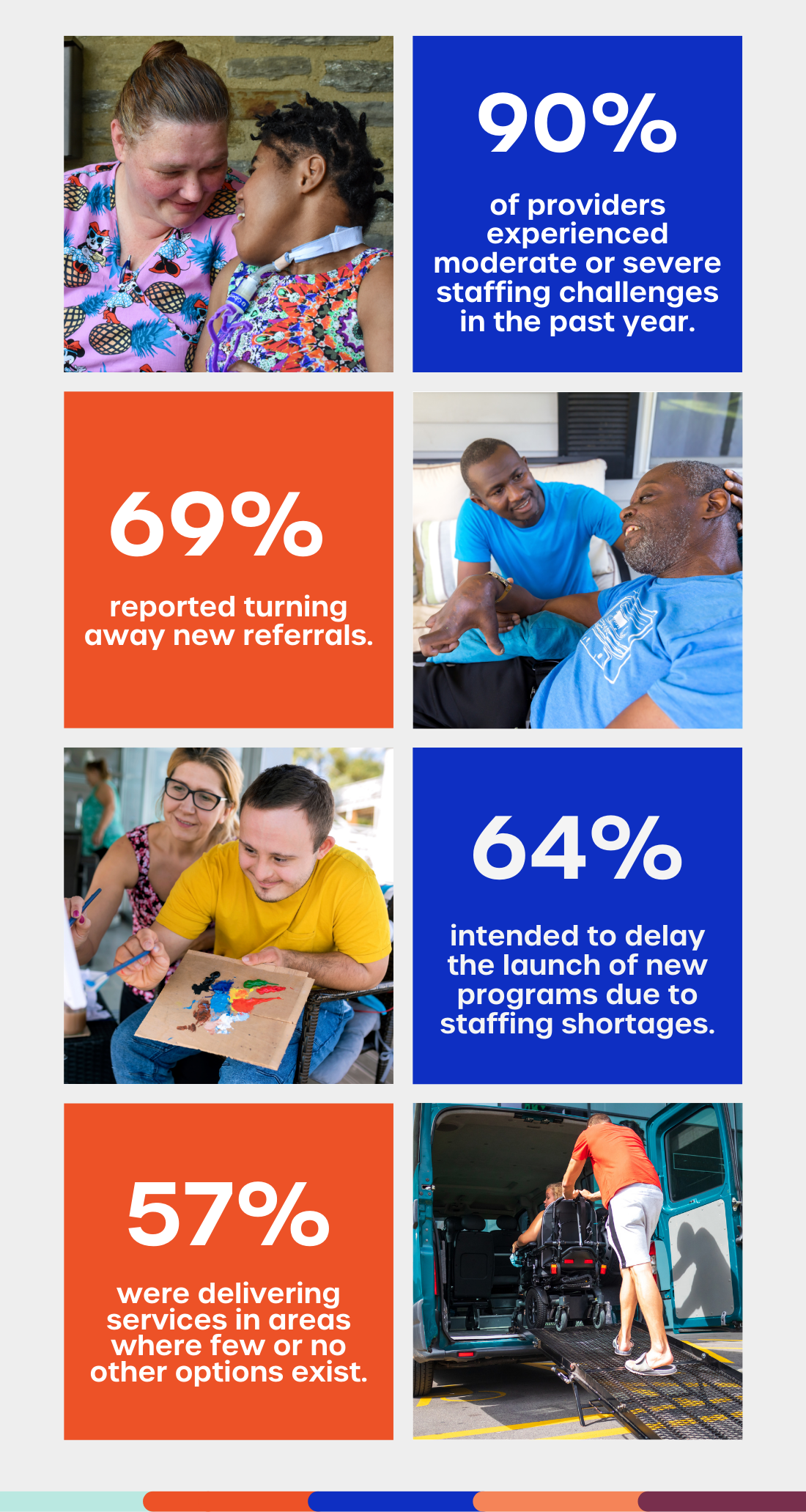
The resulting DSP workforce crisis has had a profound impact on the ability of community providers to deliver essential programs and adequately support people with I/DD in our communities.

Should Chat GPT Help With My Research?
By Carli Friedman, CQL Director of Research
It often feels like you can’t go anywhere without hearing about artificial intelligence (AI), including large language models (LLMs) like ChatGPT, these days. This hot new trend is rapidly being incorporated into software, ‘art’, education initiatives, human services, and even research. This includes qualitative research, which is research focused on words (rather than numbers), such as from interviews and focus groups.
In this new paper, along with Dr. Aleksa Owen (University of Nevada Reno), and Dr. Laura VanPuymbrouck (Rush University), I argue against the use of AI for qualitative research related to disability as it cannot uphold the standards of quality and rigorous qualitative research. To point out ethnical and methodological implications, in this study, we had two LLMs – ChatGPT and Google Gemini – complete several key components of qualitative disability research and examined the results. Below I summarize several of the key findings, although the manuscript itself provides more limitations and critiques.
To properly analyze qualitative research, the researcher must first understand what is being said, both literally and ‘between the lines.’ We had LLMs process quotes from people with intellectual and developmental disabilities (IDD) that followed non-normative communication styles. The LLMs failed to adequately process what was being said by people with IDD, often because the LLMs lacked contextual knowledge about people with IDD and their lives. In fact, sometimes the LLMs even made up information – this is often referred to as ‘hallucinating,’ and is common problem with LLMs – that the participants were not even saying, resulting in misleading interpretations of the data.
“In this new paper, along with Dr. Aleksa Owen (University of Nevada Reno), and Dr. Laura VanPuymbrouck (Rush University), I argue against the use of AI for qualitative research related to disability as it cannot uphold the standards of quality and rigorous qualitative research. ”
Another component of qualitative analysis is coding, which is when the researcher assigns labels to core sections of what the participant said; codes are then grouped into themes to represent the findings. When we asked the LLMs to assign codes to various quotes from disability research projects, they largely regurgitated the same exact language the quotes used. LLM cannot truly ‘understand’ anything, and this was indicated in these findings that were largely meaningless. The few times the LLMs did produce ‘original’ content, the findings included biased portrayals of disability, and the LLMs often hallucinated and produced findings that were not reasonable based on the quotes.
One of the ways to strengthen qualitative research is to have multiple people code the same data and compare their findings. The findings should mostly be the same but if their findings differ, they discuss the differences in depth and come to an agreement about how things should be interpreted. This is called investigator triangulation. To test investigator triangulation with the LLMs, all three of us had the LLMs code the exact same quotes on each of our computers. We found the LLMs produced different results every single time. Not only that, but the results were again largely just slices of the quotes themselves. In addition, even if a LLM was used to triangulate the data with a human, given LLMs are ‘black boxes’ that cannot explain why they make the choices they make or what informs them, it is not possible to discuss and come to consensus about differences. As such, the LLMs also failed our test of triangulation.
“We were motivated to write this piece based on the outsize promises that… have made about AI’s potential to optimize qualitative research analysis… In this commentary, we have presented a caution against the unconsidered use of AI within qualitative analysis, particularly when studying disability as a social phenomenon… because it is not able to provide quality, consistency, or credible results, demonstrating AI may not meet qualitative analysis standards… [There is an] ongoing need to address algorithmic bias, and we suggest that even in the case of AI improvements, qualitative analysis is a deeply human endeavor” (Friedman et al., 2024, pp. 19-21).
This article is a summary of the following journal manuscript: Friedman, C., Owen, A., & VanPuymbrouck, L. (2024). Should ChatGPT help with my research? A caution against artifical intelligence in qualitative research. Qualitative Research, advanced online publication. https://doi.org/10.1177/14687941241297375